Introduction
To answer some larger-scale IT requirements, the so called ‘standard’ solutions available on the market are simply not enough. The same is true for web hosting / development. This case study elaborates on how to utilize some of the most cutting-edge computing technologies available to achieve a more superior yield for this area.
The technology
Distributed computing or parallel computing is the utilization of autonomous serves which are connected via a network to achieve the same goal(s), usually an especially large one. Cloud computing on the other hand utilizes the same approach, only with greater efficiency thanks to other functionalities, including peer-to-peer resource-management for example. ‘The cloud’ as some refer to it can greatly reduce overall IT costs in some cases. The Amazon EC2 (elastic computer cloud) services which we will discuss further down the article offer similar benefits.
Cloud computing is typically chosen due to several reasons including reliability, e.g. in case one of the servers fails the network will not be crucially affected; scalability, e.g. the system can seamlessly sustain usage spikes and of course cost-efficiency, as cloud-computing can enable clients to utilize resources on-demand. The Amazon EC2 services operate on a similar basis, as clients ‘rent out’ capacity in the form of Amazon virtual servers.
The necessity and benefit
Designing and implementing a heavy web-application can be quite challenging. In case one server cannot handle the given amount of data in the necessary timeframe, a cluster of servers should be set-up for parallel processing. Parallel computing power is available in multiple forms, some of which can be quite costly if not suiting an operation, even in light of the high cost-efficiency potential cloud computing offers.
One of these is of course renting remote servers from a dedicated web host. This involves a monthly fee extended and a yearly contract where clients are required to pay a fixed amount regardless of their servers being idle or not. Another alternative is setting-up an entire data centre, but that is an even more expensive option where one will still have to invest towering setup and maintenance costs.
The two options above both require immense sums of money unreachable for certain companies and most start-ups. There is another more economical option arriving in the form of virtual servers. These can be rented and paid for by the hour only when used, rather than monthly.
Architecture
The solution below extends the use of on-demand servers, as the software overview is relevant for the following criteria:
– Data is received by a server during working hours but required to be processed at night. Results are viewed in the following business day.
– A modest amount of data is required for processing a single task (instructions) and presenting a result.
– All tasks and results have to be registered in a single database.
– Processing a single task must suit a timeframe which is not in the reach of an average server.
– The number of tasks processed overnight is quite large e.g. hundreds and thousands of tasks.
– A moderate hosting / development budget is available.
The essence behind the architecture of a server network aimed to answer the requirements above is a main virtual server receiving data (both tasks and results) during the day, and additional tens of hundreds of data processing virtual servers.
For this task, we will choose the Amazon EC2 virtual server service due to its simplicity and per hour payment availability, as well as an intermediary service to handle the task queue – Amazon Simple Queue Service (Amazon SQS). This combination can reduce hosting costs to as little as 1/6 of the cost of outsourced server capacity. Additionally, Amazon SQS is very robust at handling numerous concurrent requests, which is yet another reason it is a favorable option.
Structure
Let’s call the main server’s module DCBoss and the module installed on the data processing servers DCWorker.
DCBoss would perform two main functions:
– Receive data (tasks as well as results delivered by DCWorker).
– Dispatch tasks to DCWorker ‘instances’ AKA Amazon EC2 virtual servers, to process at non-working hours.
In order to guarantee that each and every task will be processed even in case a single instance fails to do so, one must implement a dispatcher functionality to DCBoss. This functionality enables DCBoss to submit data collected to the Task Queue detailed in the diagram below. During processing hours DCWorker instances will be ‘requesting’ tasks from the queue. Amazon SQS stores every task in the Task Queue until they have fully been processed. If one DCWorker fails to do so, the given task(s) will be made available for another instance. The same is true for the Results Queue.
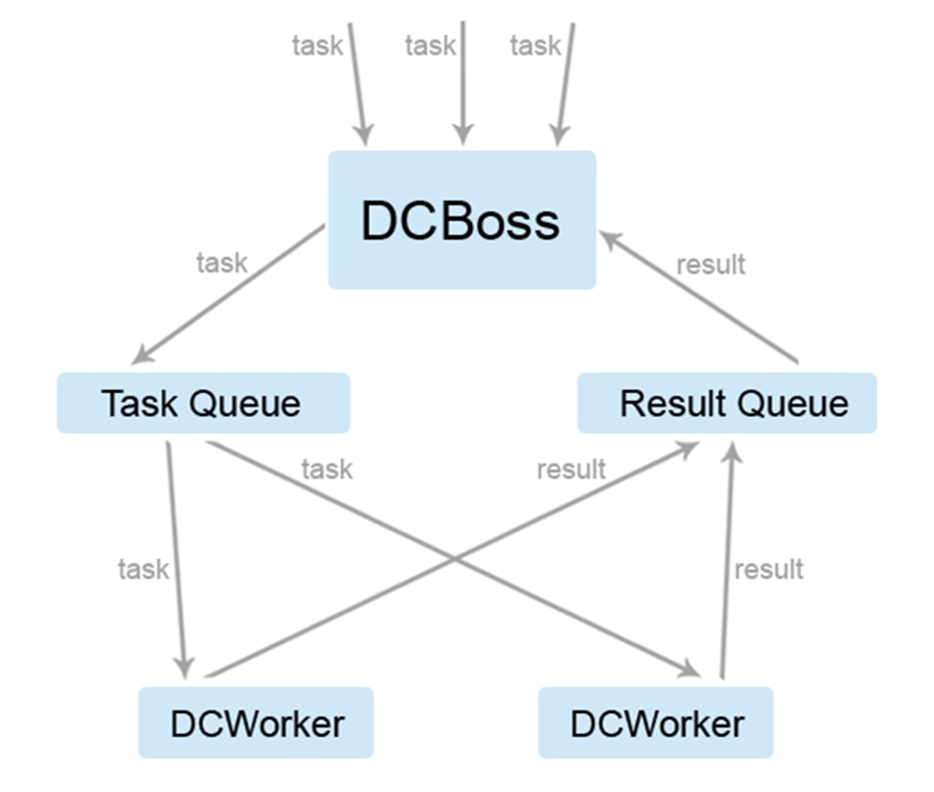
Despite of its many obvious benefits, the implementation of Amazon SQS on the server network only guarantees the delivery of messages (which we will detail further down this case study) once. Additionally, Amazon SQS doesn’t follow the FIFO – First In, First Out – approach.
Now that we’ve set-up our Amazon EC2 network and implemented Amazon SQS, we have a fairly scalable (expandable) system capable of robustly handling added workload / calculations when required to. If these exceed the capacity the system can handle, one can just add as much additional instances to the network they require.
Implementation
DCBoss and DCWorker are two completely different modules. They can be developed in different programming languages and run on different platforms as they only communicate with and via Amazon SQS. Nonetheless, the ideal option is to select a platform on which Amazon’s third party components, also known as Libraries, are available with SQL. Bespoke implementation via SQS API is also an option, but it may require additional efforts.
Integrating remote components
DCBoss and DCWorker exchange their data via Task Queue messages. These text messages contain information about given tasks and results within the system and are restricted to Amazon’s memory limitation; 8KB. If our message is for example 1KB, then we can optimize the system to send 8 message-sized packages. However, if a given message exceeds 8KB then we can use a solution proposed by Amazon: “For even larger messages, you can store the contents of the message using the Amazon Simple Storage Service (Amazon S3) or Amazon SimpleDB and use Amazon SQS to hold a pointer to the Amazon S3 or Amazon SDB object.”
Demo system
The following system is an implementation example aimed at providing visualization. Applying this in practice would require consideration of exceptions.
The DCBoss module is implemented to the system as a Java application based on the Struts framework and Typica SQS API. DCBoss allows a user to create test ‘accounts’ and process them as well as monitor execution. The user is supposed to manually initiate the DCWorker instances’ task processing by pressing a button for example, as they may see which DCWorker instance processed which account in a result report.
The DCWorker module in turn is a PHP script with a stub a piece of code ‘standing in’ for the actual calculation functionality the system utilizes. DCWorker utilizes the simple-aws library to manage Amazon SQS, as it requests tasks from the Task Queue and submits results to the Result Queue in a loop. For visualization purposes, the DCWorker instance or virtual server is an execution of a PHP class running on the same server as a separate HTTP request handler managing internet-transferred requests.
The ‘readme.txt’ file supplied in the package contains the required information about how to configure both modules.
Summary
This case study is yet another example of how the state-of-the-art technologies make answering quite nontrivial requirements absolutely straightforward and economical, including setting up economical virtual server networks.